Olson et al. (2018) – Benchmarking study (Halaman 5) – memberikan konteks penting mengapa ensemble heterogen dipilih pada data terstruktur
Additional contextual notes from slide deck IF3270 (Halaman 44)
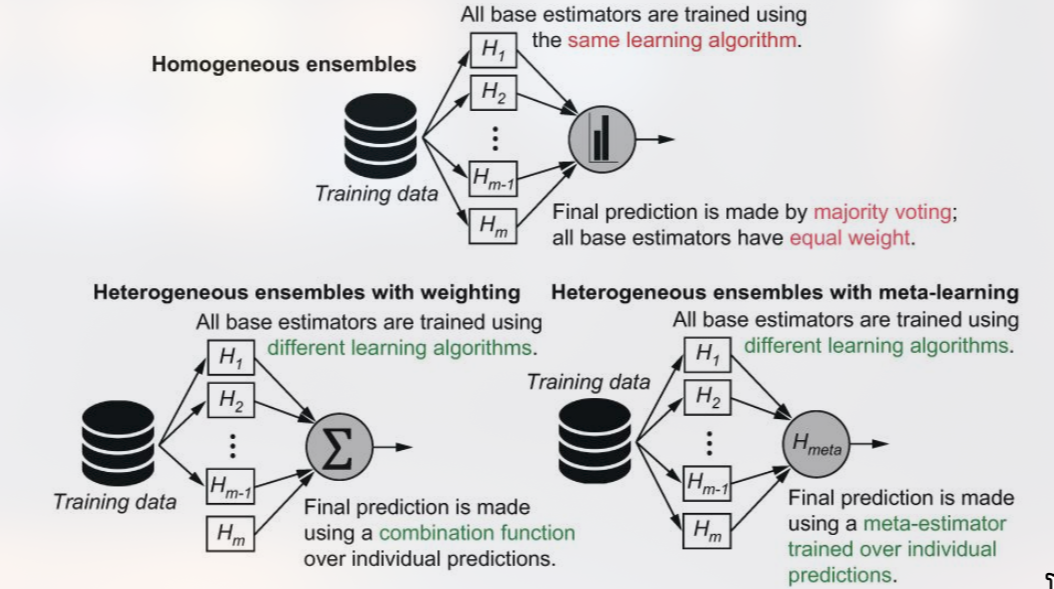
Heterogeneous Parallel Ensembles
Heterogeneous parallel ensembles adalah kumpulan model‑model dasar yang dilatih secara mandiri (paralel) menggunakan algoritma pembelajaran yang berbeda‑beda, misalnya kombinasi antara pohon keputusan, support vector machine, dan jaringan saraf tiruan. Karena tiap model memiliki asumsi, representasi fitur, dan cara generalisasi yang unik, mereka cenderung membuat kesalahan yang tidak saling tumpang‑tindih. Ketika kesalahan‑kesalahan ini digabungkan, efek “wisdom of the crowd” muncul: prediksi akhir biasanya lebih stabil dan akurat dibandingkan prediksi satu model tunggal.
Pada tahap pelatihan, setiap base learner menerima seluruh set data pelatihan (atau subset yang dipilih secara acak, tanpa harus menggunakan teknik bootstrap yang merupakan bagian dari ensemble homogen). Karena tidak ada ketergantungan antar model, proses pelatihan dapat dijalankan secara paralel pada CPU atau GPU yang berbeda, mempercepat waktu komputasi secara signifikan.
Setelah semua model selesai dilatih, mereka menghasilkan prediksi pada data validasi atau data tes, yang selanjutnya akan digabungkan menggunakan skema agregasi yang dipilih (misalnya voting, averaging, atau meta‑learning).
Penting untuk memperhatikan diversitas antar model. Diversitas dapat dicapai melalui perbedaan algoritma, variasi hyperparameter, atau transformasi fitur (misalnya, satu model menggunakan fitur asli, sementara model lain menggunakan PCA‑reduced features). Tanpa diversitas yang memadai, ensemble heterogen dapat berperilaku hampir sama dengan ensemble homogen, sehingga manfaat tambahan menjadi minim.
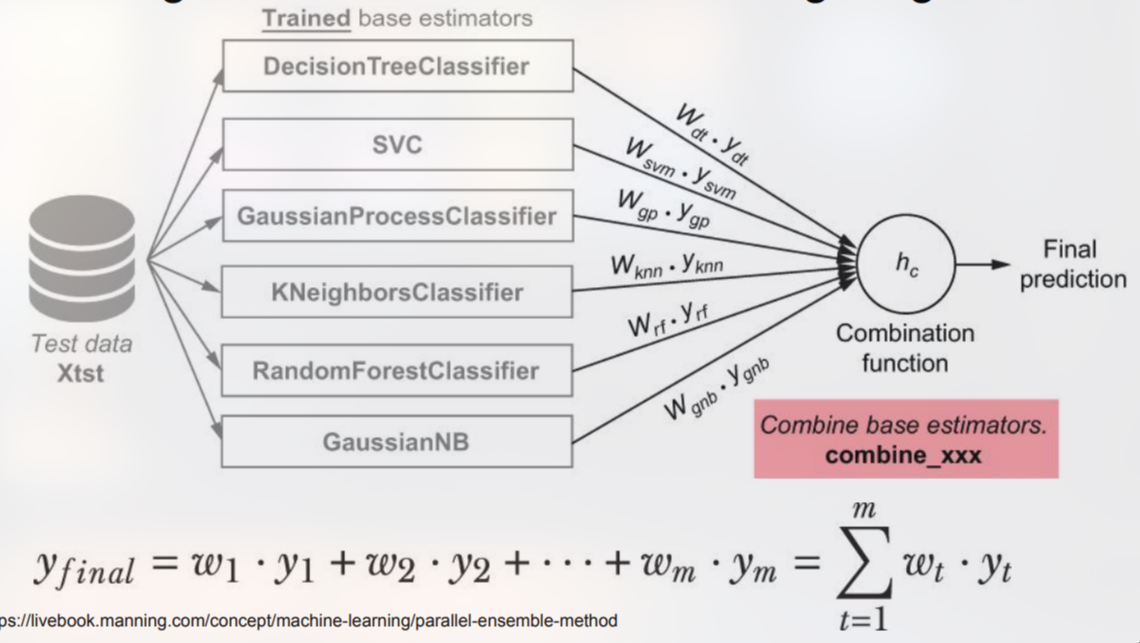
Weighting Schemes in Heterogeneous Ensembles
Pada ensemble heterogen, bobot menentukan seberapa besar kontribusi masing‑masing model terhadap prediksi akhir.
Sebelum digunakan, penting untuk menormalisasi bobot supaya berjumlah 100%
wi=∑j=1npjpi
Use case: Misalkan metriknya adalah akurasi, maka normalisasi akurasinya. Begitupun untuk F1 dan metrik lainnya.
Ada dua pendekatan utama: bobot statis/hard voting dan bobot dinamis/soft voting.
Bobot Statis biasanya dihitung satu kali setelah fase validasi, menggunakan metrik performa seperti akurasi, F1‑score, atau AUC pada data validasi. Misalnya, jika tiga model memperoleh akurasi 0,92; 0,85; dan 0,78, bobot dapat ditetapkan proporsional terhadap nilai tersebut (misalnya 0,45; 0,35; 0,20). Pendekatan ini sederhana, mudah diinterpretasikan, dan cocok ketika data tidak berubah secara signifikan di masa depan.
Secara matematis:
y^=i=1∑nwi⋅y^i
Bobot Dinamis menyesuaikan kontribusi model pada setiap contoh input. Salah satu teknik populer adalah probability‑based weighting, di mana setiap model menghasilkan distribusi probabilitas kelas, dan bobot pada contoh tertentu dihitung berdasarkan kepercayaan (confidence) model pada kelas tersebut. Contoh: pada sebuah instance, model A memberikan probabilitas 0,9 untuk kelas positif, sementara model B hanya 0,55; maka pada instance itu, bobot model A akan lebih tinggi. Teknik lain melibatkan stacked generalization (lihat bagian berikut) yang secara otomatis belajar fungsi penggabungan berbobot melalui meta‑learner.
Secara matematis:
y^=argcmaxi=1∑nwi⋅Pi(c∣x)
Contoh lagi:
3 model, 2 kelas (0 dan 1), input x tertentu:
Model 1 (w=0.5): P(kelas=1) = 0.80, P(kelas=0) = 0.20
Model 2 (w=0.3): P(kelas=1) = 0.60, P(kelas=0) = 0.40
Model 3 (w=0.2): P(kelas=1) = 0.30, P(kelas=0) = 0.70
Voting vs. Weighted Voting: Pada voting sederhana, setiap model memiliki satu suara yang sama; prediksi akhir adalah kelas dengan mayoritas suara. Pada voting berbobot, suara tiap model dikalikan dengan bobotnya, sehingga model yang lebih akurat memiliki pengaruh lebih besar. Weighted voting dapat mengurangi dampak model lemah yang secara kebetulan memberikan prediksi yang salah pada sebagian besar contoh.
Praktik Implementasi: Di scikit‑learn, kelas VotingClassifier mendukung parameter weights yang menerima list bobot. Untuk bobot dinamis, biasanya diperlukan custom aggregator yang menerima matriks probabilitas (predict_proba) dan menghitung rata‑rata berbobot secara manual.
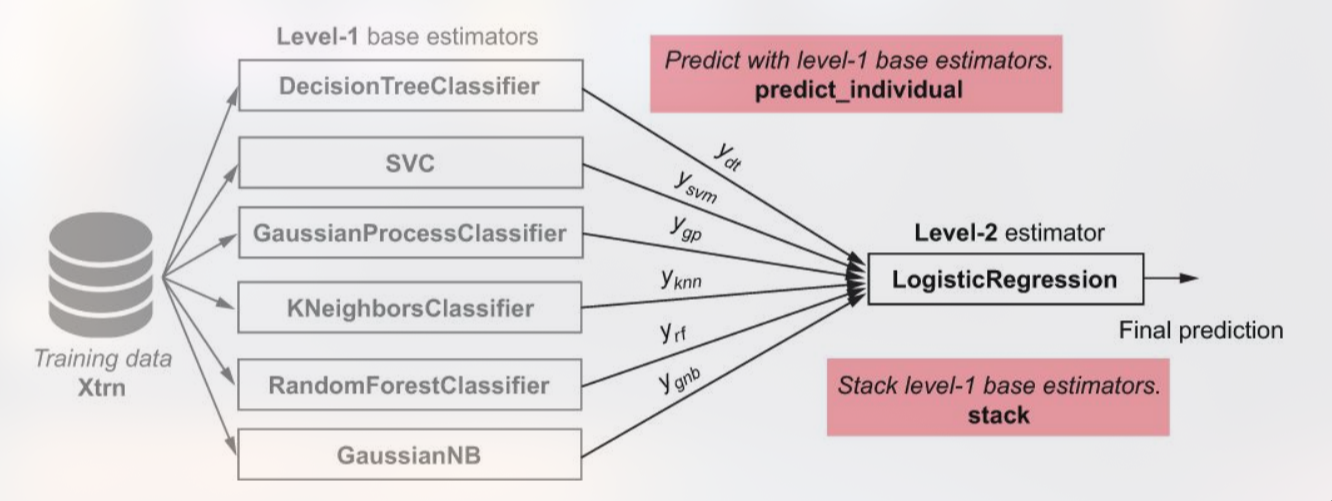
Stacking as Meta‑Learning
Stacking (atau stacked generalization) adalah teknik meta‑learning di mana prediksi dari beberapa base learner dijadikan fitur input bagi model tingkat‑dua (meta‑learner). Prosesnya terdiri dari tiga langkah utama:
Pelatihan Base Learners – Model‑model dasar (misalnya SVM, Random Forest, MLP) dilatih pada data pelatihan asli. Pada fase ini, biasanya dilakukan k‑fold cross‑validation untuk menghasilkan prediksi out‑of‑fold yang tidak bias.
Konstruksi Level‑One Dataset – Prediksi (biasanya probabilitas kelas) dari setiap base learner pada data validasi/k‑fold dikumpulkan menjadi sebuah matriks baru, di mana setiap kolom mewakili satu model. Matriks ini menjadi dataset level‑one.
Pelatihan Meta‑Learner – Model tingkat‑dua (seringkali regresi logistik untuk klasifikasi atau regresi linear untuk regresi) dilatih pada dataset level‑one. Meta‑learner belajar cara mengkombinasikan prediksi base learner sehingga mengoptimalkan performa keseluruhan.
Mengapa Stacking Efektif? Karena meta‑learner dapat mempelajari pola korelasi antar prediksi. Misalnya, dua model mungkin sering salah pada contoh yang sama; meta‑learner dapat memberi bobot rendah pada kombinasi tersebut. Sebaliknya, jika satu model unggul pada subset fitur tertentu, meta‑learner dapat meningkatkan bobotnya pada contoh‑contoh yang relevan.
Arsitektur Multi‑Level: Stacking tidak terbatas pada dua lapisan. Pada arsitektur multi‑level stacking, output dari level‑satu dapat menjadi input bagi level‑dua, dan seterusnya, membentuk hierarki yang menyerupai jaringan saraf dalam hal kedalaman. Namun, setiap penambahan level meningkatkan risiko overfitting, sehingga teknik regularisasi (seperti dropout pada meta‑learner atau penggunaan validation set terpisah) menjadi penting.
Contoh Praktis: Pada kompetisi Kaggle “Titanic”, peserta sering menggabungkan model‑model seperti Gradient Boosting, XGBoost, dan LightGBM sebagai base learners, lalu melatih logistic regression sebagai meta‑learner. Hasilnya biasanya meningkatkan skor akurasi sebesar 1‑2% dibandingkan model terbaik tunggal.
Implementasi di Python: Scikit‑learn menyediakan StackingClassifier dan StackingRegressor. Parameter penting meliputi estimators (list tuple nama‑model), final_estimator (meta‑learner), serta cv (jumlah fold). Contoh kode singkat:
Kode di atas memperlihatkan bagaimana tiga model heterogen digabungkan, kemudian logistic regression belajar mengoptimalkan kombinasi mereka.
Practical Considerations and Pitfalls
Meskipun stacking menawarkan peningkatan performa yang signifikan, ada beberapa hal yang harus diwaspadai:
Data Leakage: Jika prediksi base learner pada data pelatihan langsung digunakan tanpa cross‑validation, meta‑learner akan “melihat” jawaban sebenarnya, menghasilkan estimasi performa yang terlalu optimistik.
Kompleksitas Komputasi: Training banyak model sekaligus, terutama pada dataset besar, dapat memakan memori dan waktu yang signifikan. Penggunaan teknik paralelisasi (misalnya joblib.Parallel) atau pemilihan subset model yang lebih sedikit dapat mengurangi beban.
Ketidakseimbangan Kelas: Pada masalah klasifikasi tidak seimbang, bobot model atau teknik sampling (SMOTE, undersampling) harus dipertimbangkan sebelum stacking, agar meta‑learner tidak terbias pada mayoritas kelas.
Interpretabilitas: Semakin banyak model yang digabungkan, semakin sulit untuk menjelaskan keputusan akhir. Metode interpretasi seperti SHAP atau LIME dapat diterapkan pada meta‑learner untuk memahami kontribusi masing‑masing base learner.
Secara keseluruhan, heterogenous parallel ensembles dengan skema weighting dan stacking memberikan kerangka kerja yang fleksibel untuk memanfaatkan kekuatan beragam algoritma, sekaligus menekan kelemahan masing‑masing model melalui kombinasi yang cerdas.
Summary
Ensemble heterogen paralel menggabungkan model‑model dengan algoritma berbeda untuk memanfaatkan diversitas prediksi, sehingga meningkatkan akurasi secara keseluruhan. Skema pemberian bobot, baik statis maupun dinamis, menentukan kontribusi relatif tiap model; bobot berbobot mengurangi pengaruh model lemah dibandingkan voting sederhana. Stacking memperlakukan prediksi base learner sebagai fitur bagi meta‑learner, memungkinkan pembelajaran kombinasi yang lebih adaptif dan sering menghasilkan performa superior, asalkan dihindari data leakage dan overfitting. Implementasi praktis dapat dilakukan dengan VotingClassifier atau StackingClassifier di scikit‑learn, dengan perhatian khusus pada validasi silang dan regularisasi.
Additional Information
Advanced Weight Optimization
Optimasi bobot pada ensemble heterogen dapat dipandang sebagai masalah convex optimization. Misalkan terdapat (M) model dengan prediksi probabilitas (\mathbf{p}_i \in \mathbb{R}^K) untuk (K) kelas. Kita ingin menemukan vektor bobot (\mathbf{w} \in \mathbb{R}^M) yang meminimalkan loss log‑likelihood pada data validasi:
Persamaan di atas dapat diselesaikan dengan algoritma Projected Gradient Descent atau Sequential Quadratic Programming. Pendekatan ini menghasilkan bobot yang secara eksplisit menyesuaikan kepercayaan tiap model pada setiap kelas, berbeda dengan bobot statis yang hanya mengandalkan satu metrik performa.
Implementasi praktis dapat menggunakan library cvxpy:
Hasilnya adalah vektor bobot optimal yang dapat langsung dipakai pada aggregator berbobot.
Multi‑Level Stacking Architectures
Pada stacking berlapis, output dari level‑satu tidak hanya menjadi input bagi satu meta‑learner, melainkan dapat menjadi input bagi beberapa meta‑learner yang masing‑masing menangani sub‑masalah (misalnya, klasifikasi vs. regresi). Salah satu arsitektur populer adalah Super Learner (Van der Laan et al., 2007), yang secara teoritis menjamin performa tidak lebih buruk daripada model terbaik dalam kumpulan base learner. Super Learner menggunakan cross‑validated risk untuk menilai setiap base learner, kemudian mengoptimalkan bobot melalui regresi non‑negatif (NNLS).
Pada praktik, arsitektur tiga‑lapis dapat dirancang sebagai:
Level‑1: Berbagai model heterogen (SVM, k‑NN, MLP) menghasilkan prediksi probabilitas.
Level‑2: Dua meta‑learner paralel, misalnya Gradient Boosting dan Elastic Net, masing‑masing mempelajari kombinasi berbeda.
Level‑3: Model final (biasanya logistic regression atau neural network ringan) menggabungkan output dari level‑2.
Keuntungan utama adalah redundansi; jika satu meta‑learner gagal pada subset data, yang lain dapat menutupi. Namun, kompleksitas komputasi meningkat secara eksponensial, sehingga teknik model pruning dan early stopping menjadi penting.
Theoretical Foundations: Bias‑Variance Decomposition in Heterogeneous Ensembles
Analisis klasik bias‑variance menjelaskan mengapa ensemble dapat mengurangi variance tanpa meningkatkan bias secara signifikan. Pada ensemble homogen, semua model memiliki fungsi harapan yang sama, sehingga pengurangan variance terbatas pada korelasi antar model. Pada ensemble heterogen, fungsi harapan tiap model berbeda karena algoritma yang berbeda, sehingga bias total dapat berkurang bila model‑model tersebut melengkapi satu sama lain. Secara formal, untuk estimator (\hat{f}) yang merupakan rata‑rata berbobot:
Di sini, (\mathbb{E}[\hat{f}(x)]) merupakan rata‑rata fungsi harapan semua base learner. Jika base learner memiliki bias yang saling melengkapi (misalnya satu model under‑fits, yang lain over‑fits), rata‑rata dapat menghasilkan bias yang lebih kecil daripada masing‑masing model. Variance, di sisi lain