Back to IF3270 Pembelajaran Mesin
Backpropagation Learning Algorithm and Gradient Computation for MLPs
Questions/Cues
- Mengapa gradien dihitung mundur?
- Bagaimana error pada output memengaruhi bobot?
- Kapan harus menghentikan iterasi backprop?
- Apa peran fungsi aktivasi dalam turunan?
- Bagaimana cara mengatasi gradien menghilang?
Reference Points
- Lecture_Slides_IF3270.pdf (Pages 26-38)
- Mitchell, T. (1997). Machine Learning (Chapter 11) (Pages 31‑35)
- Raschka et al. (2022). Machine Learning with PyTorch and Scikit‑Learn (Chapter 11) (Pages 30‑34)
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning (Sections 6.2‑6.3) (Pages 29‑34)
Overview of Backpropagation Learning
Backpropagation (BP) adalah algoritma pelatihan terpusat pada jaringan saraf multilayer perceptron (MLP) yang memanfaatkan kalkulus diferensial untuk menyesuaikan bobot secara iteratif. Ide dasarnya adalah menghitung error pada output jaringan, kemudian “menyebarkan” (propagate) error tersebut ke belakang melalui setiap lapisan, sehingga setiap neuron memperoleh sinyal koreksi yang disebut delta (δ). Proses ini memungkinkan jaringan belajar dari contoh pelatihan dengan meminimalkan fungsi kerugian (loss) secara bertahap. Pada setiap iterasi, dua fase utama terjadi: forward propagation (menghitung output ŷ untuk input x) dan backward propagation (menghitung gradien ∂L/∂w untuk setiap bobot w).
Mengapa backpropagation penting? Tanpa cara sistematis menghitung gradien, penyesuaian bobot akan menjadi percobaan‑dan‑kesalahan yang tidak terarah, sehingga konvergensi menjadi sangat lambat atau bahkan tidak tercapai. Dengan memanfaatkan turunan parsial, BP memastikan bahwa setiap langkah pembaruan bergerak ke arah menurunkan nilai fungsi kerugian secara steepest descent pada ruang parameter.
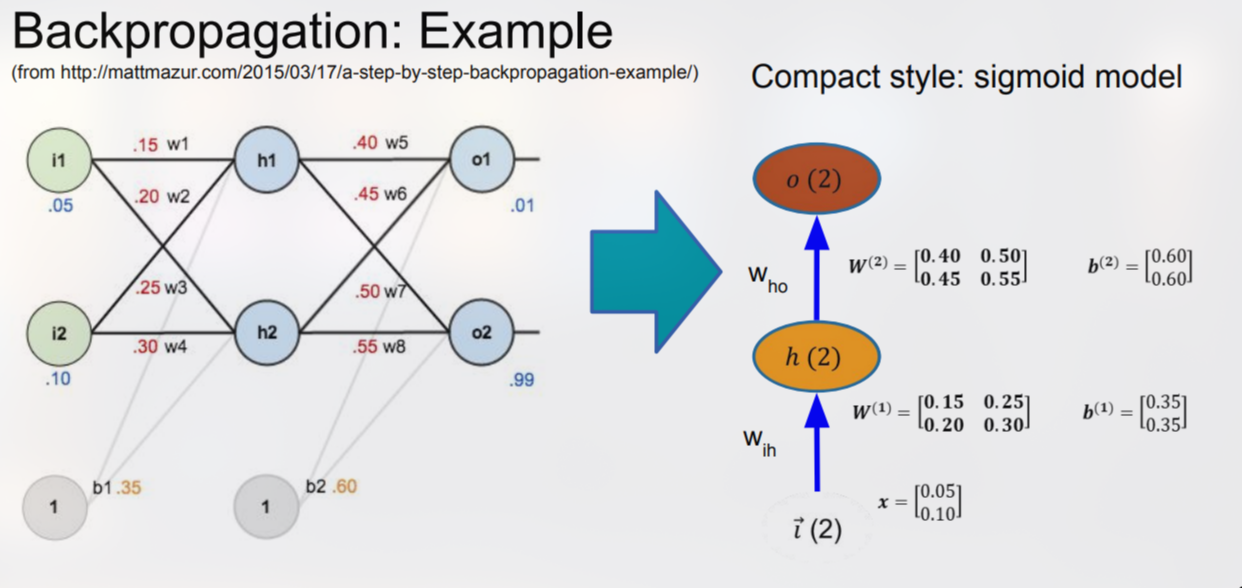
Contoh sederhana: pada jaringan dengan satu neuron output yang menggunakan fungsi sigmoid, error e = t – ŷ (target minus prediksi) dihitung. Delta pada output adalah δ_out = e·σ’(net_out), di mana σ’ adalah turunan sigmoid. Nilai δ_out kemudian dikalikan dengan output dari neuron hidden untuk memperoleh gradien bobot antara hidden dan output. Proses serupa berulang untuk lapisan sebelumnya, menghasilkan rangkaian delta yang menurun secara eksponensial dari output ke input.
Gradient Descent and the Error Surface
Gradient descent adalah strategi optimasi yang mencari titik minimum pada permukaan error (loss surface) dengan mengikuti arah negatif gradien. Pada jaringan saraf, fungsi kerugian L biasanya berupa Mean Squared Error (MSE) atau Cross‑Entropy, yang tergantung pada jenis tugas (regresi atau klasifikasi). Gradien ∇L(w) memberi tahu seberapa sensitif nilai loss terhadap perubahan masing‑masing bobot w. Dengan memperbarui bobot menggunakan aturan:
di mana α adalah learning rate, jaringan secara bertahap “menuruni” lembah‑lembah pada permukaan error. Analogi fisikanya mirip dengan bola yang meluncur turun lereng: semakin curam lereng (gradien besar), bola bergerak lebih cepat; bila lereng datar (gradien kecil), pergerakan melambat.
Pada MLP dengan fungsi aktivasi non‑linear, permukaan error menjadi non‑konveks, artinya terdapat banyak local minima dan saddle points. Oleh karena itu, pemilihan learning rate, inisialisasi bobot, dan teknik tambahan (misalnya momentum) menjadi krusial untuk menghindari terjebak pada minima yang buruk.
Contoh numerik: misalkan jaringan memiliki satu bobot w dan loss L(w)= (t‑σ(w·x))². Turunan pertama:
Dengan x=0.5, t=1, w=0.2, dan α=0.1, kita dapat menghitung nilai gradien dan memperbarui w menjadi w’ = 0.2 + 0.1·gradien. Langkah‑langkah ini diulang untuk semua bobot dalam jaringan.
Computing Gradients for the Output Layer
Pada lapisan output, gradien dihitung paling langsung karena loss L biasanya didefinisikan secara eksplisit pada output. Untuk fungsi aktivasi sigmoid , turunan pertama adalah . Jika output neuron i memiliki net input dan output , maka delta pada neuron output adalah:
di mana adalah nilai target. Gradien bobot yang menghubungkan neuron hidden j ke output i menjadi:
dengan adalah output dari neuron hidden j. Secara intuitif, delta mengukur seberapa “salah” prediksi output, dan perkalian dengan menyesuaikan bobot proporsional dengan kontribusi neuron hidden tersebut.
Contoh: jaringan XOR dengan dua hidden neuron h₁, h₂ dan satu output y. Misalkan setelah forward pass kita peroleh , target t=1, dan h₁=0.6, h₂=0.4. Maka:
Gradien untuk bobot dan . Pembaruan bobot menggunakan learning rate α=0.1 menghasilkan penurunan kecil pada kedua bobot.
Computing Gradients for Hidden Layers
Untuk lapisan tersembunyi, error tidak langsung tersedia karena tidak ada target eksplisit. Backpropagation menggunakan chain rule untuk “menyebarkan” delta dari lapisan berikutnya ke lapisan sebelumnya. Jika neuron k berada di hidden layer dengan output dan terhubung ke beberapa neuron output i, maka delta pada neuron hidden dihitung sebagai:
Di sini, adalah bobot dari hidden k ke output i, dan adalah delta yang sudah dihitung pada lapisan output. Gradien bobot antara neuron j pada lapisan sebelumnya dan hidden k menjadi:
dengan adalah aktivasi neuron sebelumnya (bisa input atau hidden lain). Proses ini berulang ke atas hingga mencapai lapisan input, menghasilkan gradient vector lengkap untuk seluruh jaringan.
Contoh numerik lanjutan: menggunakan nilai dari contoh sebelumnya, bobot , . Turunan sigmoid pada hidden (misalnya ). Maka:
Gradien untuk bobot (dengan input x₁=0.05) menjadi . Pembaruan bobot ini memperbaiki representasi hidden secara bertahap.
Weight Update Rule and Learning Rate
Setelah semua gradien dihitung, setiap bobot w diperbarui dengan aturan:
Learning rate α mengontrol ukuran langkah. Nilai α yang terlalu besar dapat menyebabkan overshooting (melewati minima) dan divergensi, sedangkan nilai terlalu kecil membuat konvergensi sangat lambat. Praktik umum adalah memulai dengan α≈0.01‑0.1 dan menurunkannya secara bertahap (learning‑rate decay) atau menggunakan teknik adaptif seperti Adam atau RMSProp.
Bias (bias term) diperlakukan sama seperti bobot, hanya saja inputnya selalu 1. Oleh karena itu, gradien untuk bias pada neuron i adalah (karena input bias =1). Pembaruan bias:
Contoh: dengan dan α=0.1, bias output baru menjadi .
Termination Criteria and Practical Considerations
Algoritma backpropagation biasanya dihentikan ketika salah satu kondisi berikut terpenuhi:
- Jumlah iterasi (epoch) tetap – misalnya 500 epoch.
- Loss pada data pelatihan turun di bawah ambang (mis. MSE < 0.001).
- Loss pada data validasi tidak membaik selama beberapa epoch (early stopping) untuk mencegah overfitting.
Selain itu, penting untuk memantau gradient exploding (gradien menjadi sangat besar) yang dapat menyebabkan nilai bobot tak terhingga. Teknik normalisasi seperti gradient clipping atau penggunaan fungsi aktivasi yang lebih stabil (mis. ReLU) dapat mengurangi masalah ini.
Pada praktik nyata, backpropagation sering dipadukan dengan mini‑batch gradient descent, di mana gradien dihitung pada subset kecil data (mis. 32 contoh) sebelum pembaruan bobot. Ini menyeimbangkan kestabilan estimasi gradien (lebih baik daripada stochastic) dan kecepatan komputasi (lebih baik daripada batch penuh).
Step-by-step Backpropagation
Setelah menebak, model harus tahu seberapa salah tebakannya dan mengevaluasi bobot mana yang harus disalahkan menggunakan kalkulus diferensial (chain rule).
Hitung Error: Bandingkan hasil prediksi (dari Forward Propagation) dengan target jawaban asli untuk mengetahui seberapa jauh tebakannya meleset.
Hitung Sinyal Koreksi (Delta) di Output: Cari tahu “nilai koreksi” untuk lapisan terakhir dengan mengalikan selisih error dengan turunan dari fungsi aktivasinya. Rumusnya: .
Dapatkan Gradien Bobot Output: Kalikan nilai delta tersebut dengan output dari hidden layer sebelumnya untuk menghitung gradien (arah perbaikan bobot): .
Mundur ke Hidden Layer: “Lempar” error tadi ke belakang menggunakan chain rule untuk menghitung delta di lapisan tersembunyi. Rumusnya: .
Dapatkan Gradien Bobot Hidden: Kalikan delta hidden layer dengan input yang masuk ke lapisan tersebut untuk mendapatkan gradiennya: .
Perbarui Bobot dan Bias (Gradient Descent): Kurangi bobot dan bias lama dengan nilai gradien yang sudah dikali ukuran langkah atau learning rate . Rumusnya: .
Iterasi: Ulangi terus fase Forward dan Backward dari awal untuk seluruh data pelatihan sampai tingkat error (loss) mencapai target kecil atau iterasi (epoch) maksimalnya habis.
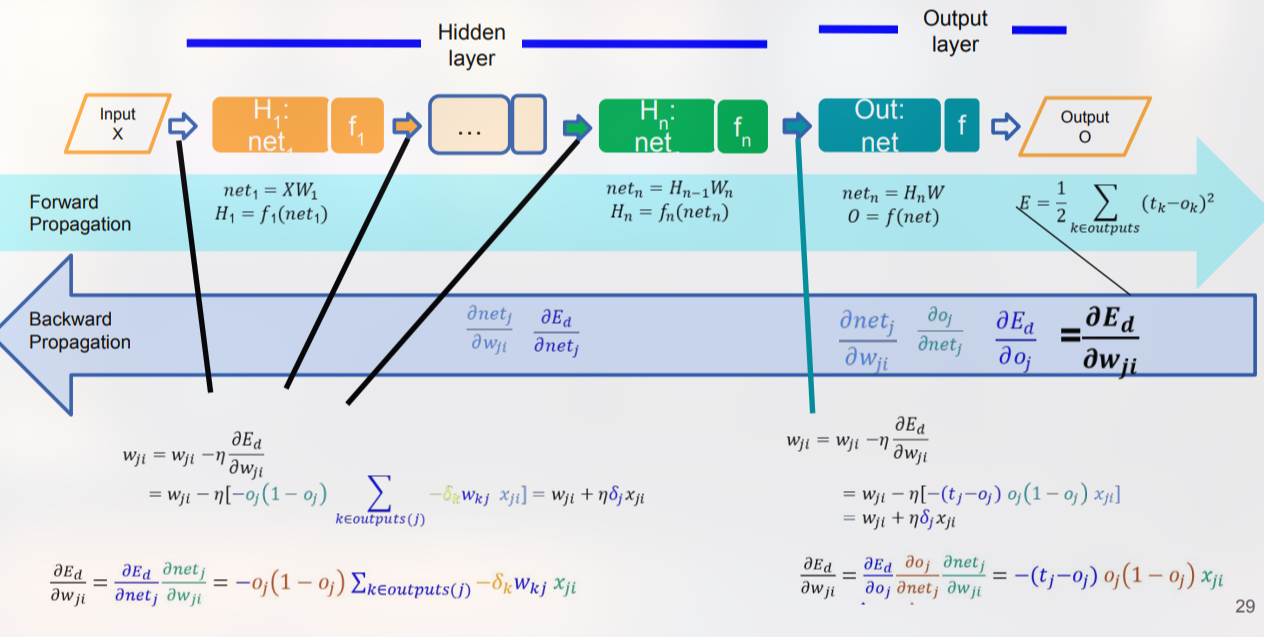

Backpropagation adalah mekanisme terstruktur yang menghitung gradien error secara mundur melalui jaringan MLP dengan memanfaatkan chain rule. Gradien pada lapisan output diperoleh langsung dari selisih prediksi‑target dan turunan aktivasi, sedangkan gradien pada lapisan tersembunyi “diturunkan” dari delta lapisan berikutnya. Dengan gradient descent dan learning rate yang tepat, bobot dan bias diperbarui secara iteratif hingga memenuhi kriteria penghentian seperti loss konvergen atau epoch maksimum. Memahami detail perhitungan delta, serta cara mengatasi masalah seperti vanishing/exploding gradients, adalah kunci untuk melatih jaringan yang efektif.
Additional Information
Formal Derivation Using Chain Rule
Misalkan fungsi loss L tergantung pada output jaringan yang pada gilirannya tergantung pada bobot melalui serangkaian fungsi aktivasi. Untuk setiap bobot, turunan total diberikan oleh:
di mana adalah aktivasi neuron j, dan . Pada lapisan output, dapat dihitung langsung dari loss (mis. untuk MSE, ). Pada lapisan tersembunyi, diperoleh dengan menjumlahkan kontribusi semua neuron berikutnya:
Kombinasi dua persamaan di atas menghasilkan rumus delta yang telah dibahas sebelumnya. Derivasi formal ini menegaskan bahwa backpropagation hanyalah aplikasi berulang dari chain rule pada graf terarah aciklik jaringan.
Variants of Gradient Descent
- Stochastic Gradient Descent (SGD) – menghitung gradien pada satu contoh pelatihan secara acak. Keuntungan: update sangat cepat, membantu keluar dari local minima, tetapi noise tinggi.
- Mini‑batch Gradient Descent – menghitung gradien pada batch kecil (biasanya 32‑256 contoh). Menyediakan kompromi antara kestabilan (seperti batch penuh) dan kecepatan (seperti SGD).
- Momentum – menambahkan fraksi dari update sebelumnya ke update saat ini:
dengan biasanya 0.9. Momentum membantu mempercepat konvergensi pada lembah‑lembah panjang.
- Adaptive Methods (Adam, RMSProp) – menyesuaikan learning rate per‑parameter berdasarkan estimasi momen pertama dan kedua gradien. Adam, misalnya, menggunakan:
dan melakukan koreksi bias sebelum pembaruan. Metode ini menjadi standar dalam banyak kerangka kerja deep learning.