Back to IF3270 Pembelajaran Mesin
Feed‑Forward Neural Network Architecture and Multi‑Layer Perceptron Design
Questions/Cues
- Mengapa jaringan feed‑forward bersifat aciklik?
- Bagaimana cara menentukan jumlah lapisan tersembunyi?
- Apa peran unit bias dalam arsitektur MLP?
- Kapan model eksplisit lebih menguntungkan daripada kompak?
- Bagaimana menghitung jumlah parameter total jaringan?
Reference Points
- Lecture_Slides_IF3270 (Pages 8‑10, 11‑13, 14‑20)
- Goodfellow et al., Deep Learning (Pages 17‑21)
- Russell & Norvig, Artificial Intelligence: A Modern Approach 4th ed. (Page 11)
- Raschka, Machine Learning with PyTorch and Scikit‑Learn (Chapter 11, Figures 11.1‑11.2)
Feed‑Forward Neural Network (FFNN) Overview
Feed‑Forward Neural Network (FFNN) adalah jaringan saraf buatan yang hanya memiliki arah aliran informasi satu arah, dari lapisan input menuju lapisan output, tanpa adanya siklus. Struktur ini dapat direpresentasikan sebagai graf terarah asiklik (DAG), di mana setiap node mewakili neuron dan setiap edge mewakili bobot yang menghubungkan neuron‑neuron pada lapisan berurutan. Karena tidak ada umpan balik, jaringan ini cocok untuk memetakan fungsi statis, seperti klasifikasi atau regresi, di mana output hanya bergantung pada input saat itu.
Pada tingkat paling dasar, FFNN memiliki lapisan input, satu atau lebih lapisan tersembunyi (hidden layers), dan lapisan output. Setiap lapisan tersembunyi biasanya terhubung penuh (fully‑connected) ke lapisan berikutnya, artinya setiap neuron pada satu lapisan memiliki bobot ke setiap neuron pada lapisan selanjutnya. Koneksi penuh ini memberikan jaringan kemampuan untuk mempelajari representasi yang sangat fleksibel.
Meskipun alur informasi bersifat satu arah, arsitektur FFNN dapat bervariasi secara signifikan dalam hal kedalaman (jumlah lapisan tersembunyi) dan lebar (jumlah neuron per lapisan). Pilihan desain ini memengaruhi kapasitas model, kompleksitas komputasi, serta kemampuan generalisasi.
Multi‑Layer Perceptron (MLP) Design
Multi‑Layer Perceptron (MLP) adalah implementasi paling umum dari FFNN, di mana semua lapisan (kecuali input) menggunakan fungsi aktivasi non‑linear. Tanpa aktivasi non‑linear, jaringan berlapis tetap dapat direduksi menjadi satu lapisan linear, sehingga tidak dapat memodelkan hubungan kompleks. Fungsi aktivasi seperti sigmoid, tanh, atau ReLU memperkenalkan non‑linearitas yang memungkinkan jaringan memetakan fungsi arbitrer.
Unit bias berperan sebagai offset yang memungkinkan neuron menggeser fungsi aktivasi secara horizontal. Secara visual, bias dapat dianggap sebagai neuron tambahan dengan nilai konstan 1 yang terhubung ke setiap neuron pada lapisan berikutnya. Kehadiran bias meningkatkan fleksibilitas jaringan, terutama ketika data tidak terpusat di sekitar titik asal.
Desain MLP biasanya mengikuti pola input → hidden₁ → hidden₂ → … → hiddenₖ → output. Setiap lapisan tersembunyi dapat memiliki ukuran yang berbeda, tergantung pada kompleksitas masalah. Misalnya, pada contoh XOR klasik, satu lapisan tersembunyi dengan dua neuron sudah cukup untuk memecahkan masalah yang tidak dapat diselesaikan oleh jaringan linear tunggal.
Contoh arsitektur eksplisit menuliskan setiap neuron dan bobot secara terpisah, memudahkan visualisasi struktur jaringan kecil. Sebaliknya, representasi kompak menggunakan notasi matriks, di mana bobot disimpan dalam matriks W dan bias dalam vektor b. Representasi kompak lebih efisien untuk implementasi komputasi karena memungkinkan operasi vektor‑matriks yang dipercepat oleh hardware.
Explicit vs. Compact Notation
Notation eksplisit menuliskan setiap neuron (misalnya, ) dan setiap bobot () secara terpisah. Kelebihannya adalah transparansi visual—pembaca dapat melihat secara langsung berapa banyak neuron dan bagaimana mereka terhubung. Namun, untuk jaringan dengan ratusan atau ribuan neuron, notasi ini menjadi tidak praktis.
Notation kompak menyatukan semua bobot lapisan ke dalam satu matriks W dan bias ke dalam vektor b. Operasi utama menjadi perkalian matriks‑vektor diikuti oleh fungsi aktivasi. Pendekatan ini memanfaatkan linear algebra untuk mempercepat perhitungan, terutama pada GPU. Selain itu, notasi kompak memudahkan analisis teoretis, seperti menghitung rank matriks bobot atau mempelajari sifat singular value decomposition (SVD) untuk memahami kapasitas representasi jaringan.
Sebagai analogi, notasi eksplisit seperti peta jalan kota yang menampilkan setiap persimpangan, sedangkan notasi kompak seperti peta kereta api yang hanya menampilkan stasiun utama dan jalur utama. Keduanya menyampaikan informasi yang sama, tetapi dengan tingkat detail yang berbeda sesuai kebutuhan.
Design Considerations: Depth, Width, and Activation Choice
Kedalaman vs. Lebar: Penelitian teoretis menunjukkan bahwa menambah kedalaman (lebih banyak lapisan tersembunyi) dapat meningkatkan kemampuan jaringan untuk merepresentasikan fungsi dengan parameter yang jauh lebih sedikit dibandingkan menambah lebar saja. Misalnya, fungsi yang memerlukan eksponensial neuron pada jaringan satu‑lapis dapat direpresentasikan dengan logaritma jumlah neuron pada jaringan berlapis‑banyak. Namun, jaringan yang terlalu dalam dapat menimbulkan masalah optimasi (vanishing/exploding gradients) meskipun hal ini berada di luar ruang lingkup pembahasan forward/backpropagation.
Pemilihan fungsi aktivasi: ReLU (Rectified Linear Unit) menjadi pilihan populer karena sifat sparsity (menghasilkan nol untuk setengah input) dan gradien konstan pada daerah positif, yang mempercepat konvergensi dalam pelatihan. Sigmoid dan tanh memberikan output terbatasi, cocok untuk lapisan output yang memerlukan probabilitas, tetapi dapat menyebabkan saturasi pada nilai ekstrim.
Ukuran lapisan tersembunyi: Praktik umum adalah memulai dengan jumlah neuron yang berada di antara ukuran input dan output, kemudian melakukan penyempurnaan (tuning) menggunakan validasi silang. Jika jaringan terlalu kecil, model akan underfit (kurang belajar pola). Jika terlalu besar, risiko overfit (mempelajari noise) meningkat, meskipun teknik regularisasi dapat mengurangi risiko tersebut.
Penggunaan unit bias: Selalu sertakan bias pada setiap lapisan kecuali pada lapisan input. Bias memungkinkan jaringan menyesuaikan hiperpipa keputusan secara fleksibel, terutama ketika data tidak terpusat pada nol.
Parameter Counting and Model Capacity
Menghitung jumlah parameter total dalam MLP penting untuk memperkirakan kapasitas model dan kebutuhan memori. Untuk setiap lapisan penuh, jumlah parameter adalah:
di mana “+1” memperhitungkan bias. Sebagai contoh, jaringan dengan arsitektur (input 8, dua lapisan tersembunyi 12 dan 8, output 1) memiliki:
Jumlah parameter ini memberi gambaran kasar tentang kompleksitas fungsi yang dapat dipelajari jaringan. Model dengan terlalu banyak parameter relatif terhadap ukuran data cenderung overfit, sementara model dengan terlalu sedikit parameter mungkin underfit.
Parameter juga memengaruhi waktu komputasi dan konsumsi energi, terutama pada perangkat edge. Oleh karena itu, perancangan arsitektur harus menyeimbangkan antara kapasitas representasi dan efisiensi sumber daya.
Step-by-step Forward Propagation
Tujuan di fase ini cuma satu: mengubah data input menjadi prediksi akhir secara deterministik, tanpa ada perubahan bobot.
Siapkan Input: Masukkan data sebagai aktivasi awal atau .
Hitung Kombinasi Linear: Kalikan input tersebut dengan matriks bobot lalu tambahkan vektor bias . Proses ini menghasilkan net input atau pre-aktivasi: .
Terapkan Fungsi Aktivasi: Masukkan hasil dari langkah 2 ke fungsi aktivasi non-linier (seperti Sigmoid atau ReLU) untuk mendapatkan sinyal output dari lapisan tersebut: .
Maju Terus: Ulangi langkah 2 dan 3 secara berurutan untuk setiap lapisan, mulai dari hidden layer pertama sampai mencapai output layer.
Dapatkan Prediksi Akhir: Output yang keluar dari lapisan paling ujung adalah tebakan atau prediksi akhir modelmu .
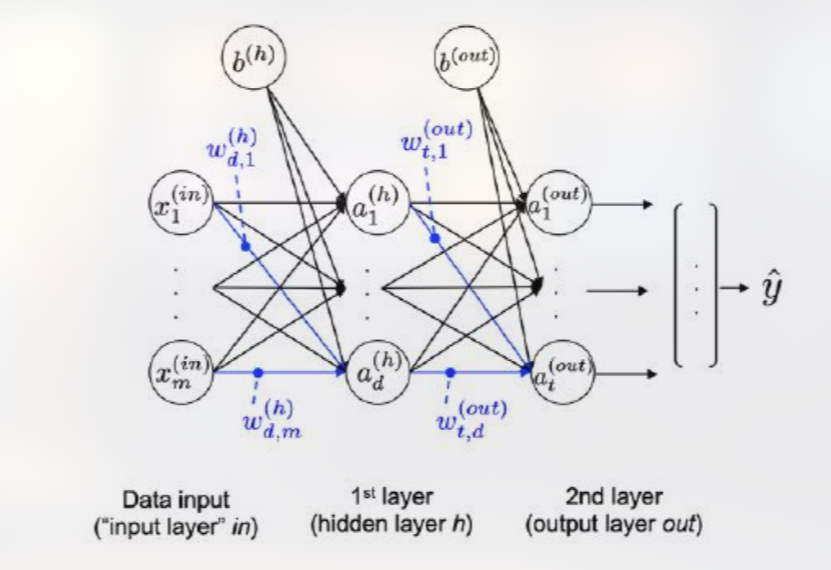
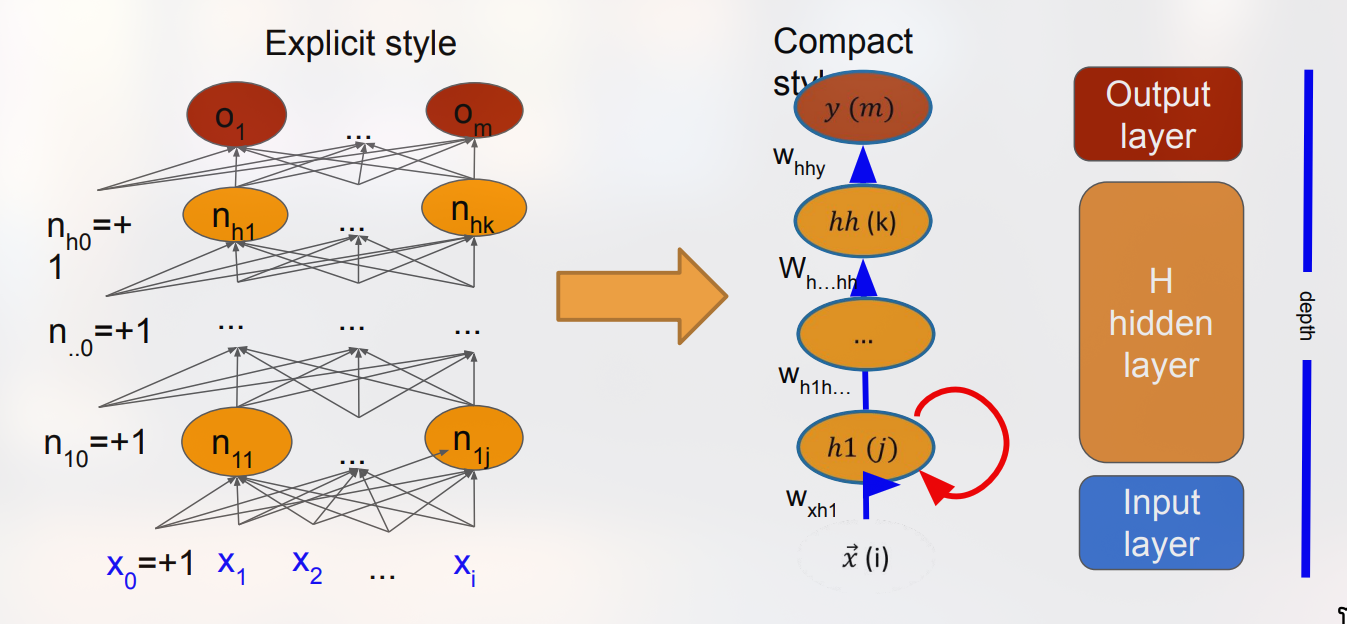
Feed‑Forward Neural Network adalah struktur aciklik yang mengalirkan informasi dari input ke output melalui satu atau lebih lapisan tersembunyi yang terhubung penuh. Multi‑Layer Perceptron menambahkan fungsi aktivasi non‑linear dan unit bias untuk meningkatkan fleksibilitas representasi, sementara notasi eksplisit dan kompak menawarkan perspektif visual dan komputasional yang berbeda. Desain arsitektur melibatkan keputusan tentang kedalaman, lebar, dan fungsi aktivasi, yang secara langsung memengaruhi kapasitas model dan jumlah parameter yang harus dikelola. Memahami hubungan ini memungkinkan perancangan jaringan yang efisien, efektif, dan sesuai dengan kebutuhan aplikasi spesifik.
Additional Information
Universal Approximation Theorem
Teorema aproksimasi universal menyatakan bahwa MLP dengan satu lapisan tersembunyi yang memiliki jumlah neuron tak terbatas dan menggunakan fungsi aktivasi non‑linear yang bersifat batasan kontinu (misalnya sigmoid atau ReLU) dapat mendekati setiap fungsi kontinu pada ruang kompak sekecil apapun. Implikasi praktisnya adalah bahwa, secara teoritis, jaringan sederhana sudah cukup untuk mempelajari fungsi apa pun, asalkan memiliki cukup neuron. Namun, dalam praktik, menambah kedalaman seringkali lebih efisien daripada menambah lebar secara tak terbatas, karena kedalaman memungkinkan komposisi fungsi yang lebih terstruktur.
Beberapa varian teorema (Cybenko 1989; Hornik 1991) memperluas hasil ini ke fungsi aktivasi lain dan menunjukkan bahwa parameter yang cukup dapat menghasilkan representasi arbitrer. Meskipun teorema tidak memberikan panduan tentang berapa banyak neuron yang diperlukan, ia memberikan dasar teoretis kuat untuk penggunaan MLP dalam hampir semua tugas pemetaan fungsi.
Depth vs. Width: Theoretical Insights
Penelitian modern (Telgarsky 2016; Eldan & Shamir 2016) membandingkan efisiensi representasi antara jaringan dalam (deep) dan lebar (wide). Hasil utama menunjukkan bahwa ada kelas fungsi yang dapat direpresentasikan dengan polinomial ukuran jaringan dalam, tetapi memerlukan ekspansial ukuran jaringan lebar. Sebaliknya, fungsi yang sangat sederhana dapat direpresentasikan oleh jaringan lebar dengan sedikit lapisan. Ini menegaskan pentingnya memilih kedalaman yang tepat berdasarkan sifat data dan kompleksitas target fungsi.
Analisis ini biasanya menggunakan kompleksitas Kolmogorov‑Arnold atau VC‑dimension untuk mengukur kapasitas jaringan. Kedalaman menambah hierarki fitur yang dapat mengekstrak pola tingkat tinggi secara bertahap, mirip dengan cara otak manusia memproses informasi secara berlapis.
Weight Initialization Strategies
Meskipun tidak membahas proses pelatihan, pemilihan strategi inisialisasi bobot sangat penting karena memengaruhi landscape error yang akan dijelajahi algoritma optimasi. Metode populer meliputi:
- Inisialisasi Xavier/Glorot (untuk aktivasi sigmoid/tanh) yang menyeimbangkan varians input dan output pada setiap lapisan.
- Inisialisasi He (untuk ReLU) yang memperhitungkan fakta bahwa setengah neuron akan “mati” (output nol) pada setiap iterasi.
- Inisialisasi ortogonal yang menjaga ortogonalitas antar bobot, membantu mengurangi korelasi antar neuron.
Pemilihan inisialisasi yang tepat dapat mencegah vanishing/exploding activations, yang pada gilirannya mempermudah proses pelatihan meskipun detail algoritma pelatihan tidak dibahas di sini.
Regularization Techniques Specific to Architecture
Untuk mengendalikan overfitting pada jaringan yang memiliki banyak parameter, beberapa teknik regularisasi dapat diterapkan pada level arsitektur:
- Dropout: secara acak menonaktifkan persentase neuron selama pelatihan, memaksa jaringan belajar representasi yang lebih robust.
- Batch Normalization: menormalkan aktivasi pada setiap mini‑batch, mempercepat konvergensi dan memberikan efek regularisasi ringan.
- Weight Decay (L2 regularization): menambahkan penalti pada besaran bobot dalam fungsi loss, mendorong bobot menjadi lebih kecil dan model menjadi lebih sederhana.
Meskipun teknik‑teknik ini biasanya diimplementasikan dalam fase pelatihan, pemahaman konseptualnya penting saat merancang arsitektur, karena mereka dapat memengaruhi keputusan tentang jumlah neuron dan kedalaman yang optimal.
Self-Exploration Projects
- Eksperimen Kedalaman vs. Lebar: Buat tiga MLP dengan total parameter yang sama (misalnya 10.000) tetapi dengan kombinasi kedalaman‑lebar yang berbeda (mis. 2‑lapis 100 neuron vs. 5‑lapis 30 neuron). Evaluasi performa pada dataset klasifikasi standar (mis. MNIST) dan analisis trade‑off antara akurasi dan waktu inferensi.
- Analisis Dampak Bias: Implementasikan dua versi MLP identik, satu dengan bias pada setiap lapisan dan satu tanpa bias. Bandingkan kemampuan jaringan dalam mempelajari fungsi non‑linear sederhana (mis. XOR) dan catat perbedaan dalam error training serta kebutuhan epoch.
Tools and Resources
- PyTorch – library Python untuk membangun jaringan dengan notasi kompak (torch.nn.Linear, torch.nn.Module). Dokumentasi resmi menyediakan contoh arsitektur MLP.
- TensorFlow/Keras – meskipun contoh Keras tidak dibahas, API
tf.keras.layers.Densememungkinkan definisi