Back to IF3270 Pembelajaran Mesin
Forward Propagation Mechanics in Feed‑Forward Neural Networks
Questions/Cues
- Mengapa bias penting dalam forward propagation?
- Bagaimana fungsi aktivasi mengubah sinyal?
- Apa perbedaan perhitungan vektor vs skalar?
- Bagaimana mini‑batch mempengaruhi output jaringan?
- Mengapa ReLU lebih cepat daripada sigmoid?
- Bagaimana cara menulis persamaan forward secara matriks?
- Apa yang terjadi pada nilai ekstrem pada aktivasi?
Reference Points
- Lecture_Slides_IF3270 (Pages 14‑20)
- Goodfellow_Bengio_Courville _DeepLearning (Pages 17‑20)
- Raschka_ML_with_PyTorch (Page 15‑16)
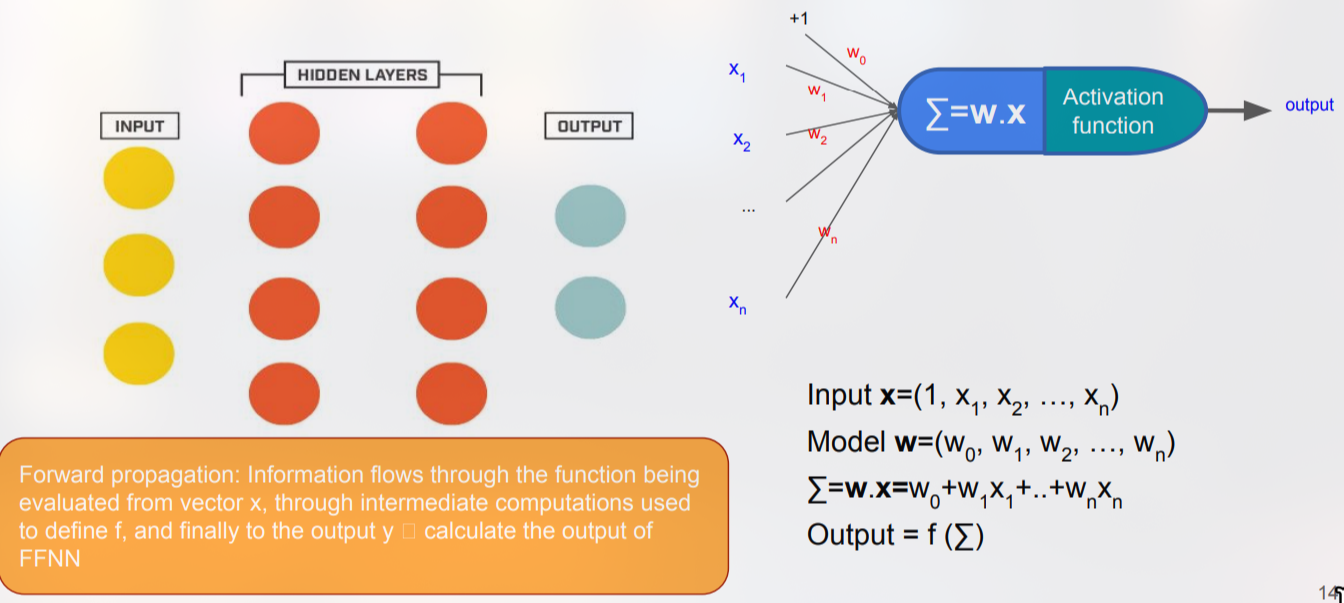
Pengantar Forward Propagation
Forward propagation adalah proses menghitung keluaran jaringan saraf tiruan (ANN) dengan cara mengalirkan sinyal input melalui setiap lapisan secara berurutan, mulai dari lapisan input, melewati satu atau lebih lapisan tersembunyi, hingga mencapai lapisan output. Pada setiap neuron, sinyal yang masuk dikalikan dengan bobot‑bobot yang terhubung, ditambahkan dengan bias, kemudian diproses oleh fungsi aktivasi. Hasil akhir dari lapisan terakhir merupakan prediksi model untuk contoh input yang diberikan. Proses ini sepenuhnya deterministik; tidak ada pembaruan bobot atau perhitungan gradien yang terjadi pada tahap ini. Karena sifatnya yang terstruktur, forward propagation dapat diimplementasikan secara vektorisasi, yang memungkinkan komputasi paralel pada GPU atau CPU modern.
Pada jaringan feed‑forward, tidak ada umpan balik (loop) sehingga aliran sinyal hanya bergerak satu arah, membentuk graf berarah tanpa siklus (directed acyclic graph). Hal ini memastikan bahwa setiap neuron hanya dipengaruhi oleh neuron‑neuron pada lapisan sebelumnya, sehingga perhitungan dapat dilakukan secara berurutan tanpa ketergantungan siklik.
Representasi Matematis: Vektor dan Matriks
Misalkan kita memiliki vektor input dan bobot‑bobot yang menghubungkan lapisan input ke lapisan tersembunyi pertama disimpan dalam matriks , di mana adalah jumlah neuron pada lapisan tersembunyi. Bias untuk lapisan tersebut disimpan dalam vektor . Maka pre‑aktivasi (net input) pada lapisan pertama dapat dituliskan sebagai:
Selanjutnya, fungsi aktivasi (misalnya sigmoid, tanh, atau ReLU) diterapkan secara elemen‑wise:
Proses ini diulang untuk setiap lapisan dengan notasi umum:
Pada lapisan output , menjadi vektor prediksi . Representasi matriks ini memungkinkan seluruh batch data diproses sekaligus dengan operasi matriks‑vektor, yang secara signifikan mempercepat komputasi dibandingkan menghitung setiap contoh secara terpisah.
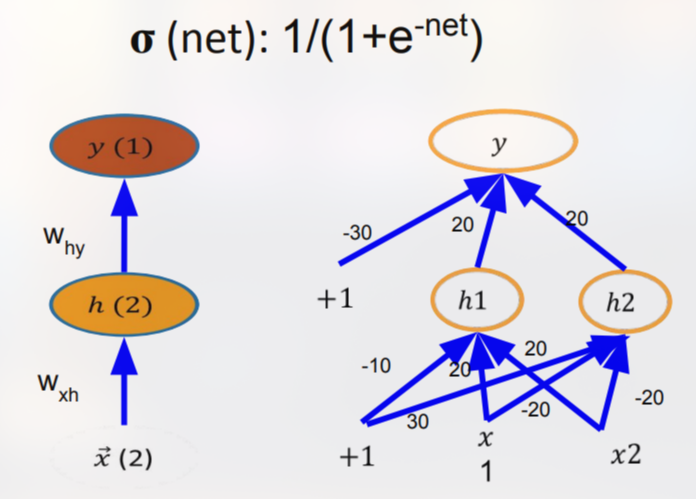
Contoh XOR dengan Sigmoid
Salah satu contoh klasik yang memperlihatkan kekuatan forward propagation adalah jaringan dua‑lapis yang menyelesaikan fungsi XOR. Dengan dua input , dua neuron tersembunyi, dan satu neuron output, bobot‑bobot serta bias dipilih sebagai berikut:
di mana adalah fungsi sigmoid. Dengan menghitung nilai untuk setiap kombinasi , jaringan menghasilkan output yang mendekati target XOR (0 untuk (0,0) dan (1,1), 1 untuk (0,1) dan (1,0)). Contoh ini menegaskan bahwa jaringan dengan satu lapisan tersembunyi dapat mempelajari fungsi non‑linier yang tidak dapat diselesaikan oleh perceptron tunggal.
Aktivasi ReLU dan Linear pada Mini‑Batch
Contoh lain menggunakan fungsi aktivasi ReLU () pada lapisan tersembunyi dan fungsi linear pada lapisan output. Misalkan bobot ke neuron tersembunyi pertama adalah dan ke neuron kedua dengan bias masing‑masing dan . Untuk sebuah input vektor :
Output linear kemudian dihitung sebagai:
yang secara sederhana mengalikan aktivasi tersembunyi dengan bobot output . Pada mini‑batch, misalkan kita memiliki tiga contoh input yang disusun menjadi matriks . Operasi forward dapat dituliskan secara vektorisasi:
di mana adalah matriks bobot input‑ke‑hidden, bias tersembunyi (ditambahkan ke setiap baris), dan bobot hidden‑ke‑output. Pendekatan ini memungkinkan komputasi seluruh batch dalam satu langkah matriks‑vektor, yang sangat efisien pada GPU.
Peran Bias dalam Forward Propagation
Bias () berfungsi sebagai offset yang memungkinkan neuron menghasilkan nilai non‑nol bahkan ketika semua input bernilai nol. Secara geometris, bias memindahkan hyperplane keputusan pada ruang fitur, sehingga jaringan dapat menyesuaikan posisi batas keputusan tanpa mengubah arah gradien bobot. Tanpa bias, semua neuron akan melewati titik asal (origin) pada ruang aktivasi, yang secara signifikan membatasi kemampuan representasi jaringan, terutama pada lapisan pertama.
Pada implementasi matriks, bias biasanya ditambahkan dengan memperluas vektor input dengan satu komponen konstan (sering disebut ) sehingga bobot bias menjadi bagian dari matriks . Alternatifnya, bias dapat diperlakukan sebagai vektor terpisah yang ditambahkan setelah perkalian matriks, seperti yang ditunjukkan pada persamaan . Kedua cara menghasilkan nilai yang identik, namun pendekatan pertama memudahkan implementasi dalam bahasa pemrograman yang mendukung operasi broadcasting.
Pengaruh Fungsi Aktivasi Terhadap Nilai Ekstrem
Fungsi aktivasi tidak hanya menambah non‑linieritas, tetapi juga mempengaruhi skala nilai yang mengalir ke lapisan berikutnya. Sigmoid, misalnya, memampatkan nilai ke rentang (0,1), sehingga gradien yang sangat kecil dapat muncul pada nilai yang sangat besar atau sangat kecil (fenomena vanishing gradient). ReLU, di sisi lain, mempertahankan nilai positif apa adanya dan memotong nilai negatif menjadi nol, yang menghasilkan gradien konstan (1) untuk nilai positif dan mengurangi risiko vanishing. Namun, ReLU dapat menghasilkan dead neurons bila semua input ke neuron tersebut selalu negatif, sehingga outputnya tetap nol selama pelatihan.
Pemilihan fungsi aktivasi harus mempertimbangkan sifat data dan tujuan model. Pada jaringan yang dalam, kombinasi ReLU pada lapisan tersembunyi dan fungsi linear atau softmax pada lapisan output sering memberikan keseimbangan antara stabilitas numerik dan kemampuan representasi.
Kompleksitas Komputasi Forward Pass
Jika sebuah jaringan memiliki total parameter (bobot + bias), maka satu forward pass pada satu contoh input memerlukan operasi perkalian‑penjumlahan. Pada mini‑batch berukuran , kompleksitas menjadi karena setiap contoh diproses secara paralel dalam operasi matriks‑vektor. Pada GPU modern, operasi ini dapat dipercepat hingga ratusan kali lipat dibandingkan CPU karena kemampuan SIMD (single instruction, multiple data) dan memori yang dioptimalkan untuk operasi dense linear algebra.
Memahami kompleksitas ini penting bagi perancangan arsitektur yang efisien, terutama ketika model harus dijalankan pada perangkat dengan sumber daya terbatas (misalnya, smartphone atau embedded system). Teknik seperti weight pruning atau quantization dapat mengurangi tanpa mengorbankan akurasi secara signifikan, sehingga mempercepat forward propagation pada tahap inferensi.

Forward propagation pada jaringan feed‑forward mengubah vektor input menjadi output melalui serangkaian operasi linier (perkalian bobot, penambahan bias) yang diikuti fungsi aktivasi non‑linier. Representasi matriks memungkinkan komputasi batch yang efisien, sementara pilihan fungsi aktivasi (sigmoid, ReLU, linear) mempengaruhi skala nilai dan stabilitas numerik. Contoh klasik XOR menunjukkan kemampuan jaringan dua‑lapis memodelkan fungsi non‑linier, dan penambahan bias serta penggunaan mini‑batch memperluas fleksibilitas serta kecepatan inferensi. Memahami detail ini memberikan landasan kuat untuk membangun, mengoptimalkan, dan menerapkan model ANN pada berbagai tugas praktis.
Additional Information
Formal Matrix Derivation of Forward Pass
Misalkan jaringan memiliki lapisan, masing‑masing dengan ukuran (di mana adalah dimensi input dan adalah dimensi output). Untuk setiap lapisan kita definisikan:
Forward pass dapat dituliskan secara rekursif:
Jika kita menggabungkan semua lapisan menjadi satu fungsi komposit dengan , maka:
Persamaan ini menegaskan bahwa forward propagation adalah evaluasi berulang dari fungsi komposisi, yang dapat dioptimalkan secara otomatis oleh kerangka kerja seperti TensorFlow atau PyTorch melalui computational graph.
Numerical Stability and Log‑Space Computations
Pada fungsi aktivasi eksponensial seperti sigmoid atau softmax, nilai dapat melampaui rentang representasi floating‑point, menghasilkan overflow atau underflow. Praktik umum untuk meningkatkan stabilitas numerik meliputi:
- Pengurangan maksimum: Pada softmax, menghitung sebelum eksponensiasi.
- Clipping: Membatasi nilai input ke fungsi aktivasi dalam rentang (misalnya ) untuk menghindari nilai ekstrem.
- Penggunaan fungsi log‑sigmoid: Menghitung log‑likelihood secara langsung tanpa mengekspresikan sigmoid, yang mengurangi risiko underflow pada nilai sangat negatif.
Implementasi yang memperhatikan stabilitas ini penting terutama pada model yang beroperasi pada data dengan skala besar atau pada perangkat dengan presisi floating‑point terbatas (misalnya, 16‑bit float pada GPU).
Forward Pass pada Convolutional Layers (Ekstensi)
Meskipun fokus utama catatan ini adalah jaringan fully‑connected, prinsip forward propagation tetap berlaku pada lapisan konvolusional. Pada lapisan konvolusi, operasi linier digantikan oleh cross‑correlation antara input dan filter kernel :
di mana